
一、AI算力的阿喀琉斯之踵:铜缆互连的三重枷锁
大模型集群算力持续狂飙,数万块GPU协同训练已成常态。但一个被忽视的瓶颈正在锁死AI算力上限:传统的铜缆电互连逐步撞上物理天花板。
随着速率迈向800G、1.6T时代,铜介质电互连陷入了三重物理枷锁:
带宽层面的指数飙升
电信号串扰与损耗随频率呈指数级增长,224G电SerDes架构成本暴涨、稳定性下滑,难以支撑超高密度算力集群。工程师们发现,当传输速率超过一定阈值后,铜缆的性能提升与成本投入已经不成正比。
延迟层面的致命短板
铜缆传输延迟是光纤的10倍以上。在分布式训练场景下,GPU之间需要频繁同步梯度数据,毫秒级的延迟会被放大成数小时的额外训练时间。这不仅拉长了训练周期,更大幅降低了GPU集群的整体利用率。
功耗层面的成本失控
这是最致命的问题。现代数据中心单机架互连功耗占比已突破40%,在万卡级GPU集群中,互连耗电成为成本失控的核心源头。每个数据中心都在算账:为了提升算力而增加的电费,正在吞噬AI训练带来的收益。
本质来看,电子传输天生存在距离损耗、频率约束,在1.6T超高速时代,铜互连的物理边界已经触顶。而光传输损耗低、速率高、距离无约束,光速更是电子运动速度的300倍——架构替代已是大势所趋。
二、硅光子技术:从“改良”到“革命”的底层跃迁
硅基光子技术并非对铜缆的简单改良,而是从底层物理介质的全面切换。其本质在于利用标准CMOS工艺在绝缘体上硅(SOI)晶圆上制造光子集成器件,实现光信号的产生、调制、传输、探测与交换。
核心原理:用CMOS工艺做光学芯片
硅光子利用硅材料在通信波段(1310nm与1550nm)的高折射率差来构建光波导,通过全内反射传导光信号。调制主要依赖载流子色散效应——通过施加电压改变波导区域内的载流子浓度,从而调制硅的折射率和吸收系数,实现高速电光调制。
但硅本身是间接带隙材料,无法高效发光。这是硅光子技术面临的根本性挑战。解决方案主要有两个:一是通过异质集成(如晶圆级键合)将III-V族材料的激光器与硅基芯片耦合;二是采用外部光源通过光纤注入。
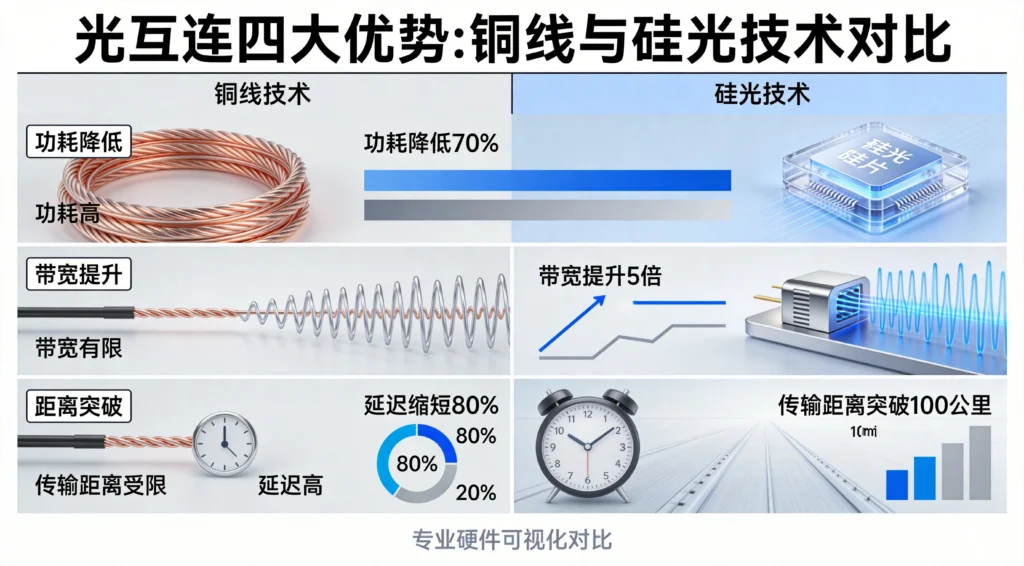
光互连的四大优势:降维打击传统电互连
光互连对传统电互连的优势,可以用“降维打击”来形容:
1. 功耗大幅腰斩
CPO(光电共封装)将光电转换模块嵌入芯片封装内部,大幅缩短高损耗电链路,单比特传输功耗从15 pJ/bit降至5 pJ/bit,远期可突破1 pJ/bit。实测数据显示,硅光替代铜互连后,整体互连功耗下降超60%。
2. 带宽密度指数跃升
光互连天生支持波分复用,单根光纤多路并行传输,带宽密度远超铜缆。台积电的硅光路线清晰:1.6T、6.4T、12.8T三级迭代,封装内带宽将远超当下HBM存储互连规格,撑起超算级数据交换需求。
3. 延迟大幅压缩
封装级光电集成,将电信号路径压缩至微米级,传输延迟降低**80%**以上。大模型分布式训练高度依赖数据实时同步,更低延迟能够减少等待损耗,加速模型收敛,大幅提升整体算力产出效率。
4. 打破距离枷锁
铜缆几米之外信号快速衰减,而光纤远距离传输几乎无损耗,可实现跨机柜、跨机房的芯片级低时延直连,为全域算力调度、大型智算集群组网打下底层基础。
三、2026年:硅光子产业拐点已至
硅光子爆发,是技术成熟、市场刚需、生态完善三重共振的必然结果。全球半导体巨头已锁定明确的量产时间表,一场围绕光电集成的军备竞赛已经打响。
台积电COUPE硅光整合平台:2026年量产
台积电的COUPE(Co-packaged Optical Universal Engine)硅光整合平台依托SoIC 3D堆叠、CoWoS先进封装,2026年正式量产,实现光电异构集成。这意味着硅光子技术将从实验室走向大规模商用,真正进入产业化阶段。
三星硅光路线图:2027筑基2028集成
在OFC 2026光通信会议上,三星正式公布硅光子学路线图:2027年技术筑基,2028年实现硅光器件与AI芯片的全面集成。更长远的目标是2029年推出GPU+内存+硅光一体化封装产品。
英特尔以EMIB封装切入定制化硅光方案,深耕高端客户市场;英伟达Spectrum-X CPO交换机已量产落地,AMD处理器原生集成光学模块。头部厂商的全面落地验证,标志着硅光子技术从“概念验证”进入“规模化应用”阶段。
市场端需求爆发
800G、1.6T高速光模块2026年出货翻倍,硅光在高端光模块渗透率突破50%。国内产业链同步提速,8英寸硅光芯片产线落地,224G高速光调制器实现突破,云厂商大规模启动硅光设备测试。
四、加州理工的突破:让光子芯片追上摩尔定律
2026年2月,加州理工学院发布了一项重量级成果:他们研发出一种方法,可将与光纤材质相同的材料制成的光学电路,直接印制到计算机芯片所用的晶圆上。
这项突破首次将光纤的超低损耗特性与硅基芯片制造流程完美结合,让光子芯片从实验室走向规模化生产成为可能。
突破的核心:原子级光滑表面
研究团队的巧思在于,直接采用与光纤同源的锗硅酸盐玻璃,通过光刻技术在8英寸或12英寸的硅晶圆上“打印”出纳米级波导。更关键的是,他们利用这种材料熔点较低的特性,增加了一道“回流”处理工序:将芯片放入炉中加热,让波导表面自然流动,最终达到原子级的光滑度。
而此前数据中心广泛使用的氮化硅,由于熔点太高,无法进行类似处理,表面粗糙度限制了性能。
基于该平台制备的激光器件,其相干时间较上一代技术提高了100多倍,这为高精度应用奠定了基础。
为什么能搭上摩尔定律快车
摩尔定律的本质并非仅仅是尺寸缩小,而是在兼容现有制程的基础上,实现性能与集成度的持续、规模化迭代。加州理工的突破恰恰击中了这两个要害:
制造兼容性:首次实现高性能光子材料与成熟硅基芯片制造工艺的100%兼容。这意味着光子芯片可以利用全球现有的晶圆厂设备进行大规模生产,成本有望大幅降低。
性能可迭代:低损耗特性是提升光子芯片集成度的前提。研究团队指出,这仅是“入门级”成果,通过调整材料成分、优化工艺,性能还有巨大提升空间。
五、现实难题:量产落地的多重硬约束
前景确定,但短期瓶颈依旧突出。硅光子规模化普及,仍需攻克工程与商业化难题。
热管理难题
光电同封装设计,叠加GPU高功耗发热,温度漂移会导致光器件性能波动,谐振器、调制器稳定性下降。这需要新型液冷、微流体散热方案配套落地。
封装耦合精度壁垒
光纤与硅光波导尺寸差距巨大,纳米级对准要求严苛,耦合损耗高、良率偏低,是制约大规模量产的核心工艺卡点。
成本与良率压力
当前硅光芯片良率不足60%,3D光电封装造价昂贵,短期替换现有铜缆架构成本过高。行业普遍共识:硅光子是长期战略方向,但不会一步到位,将伴随老旧互联技术淘汰,渐进式替代落地。
六、战略纵深:不止解决互连,重构后摩尔时代格局
硅光子的价值,早已超越“提速降耗”的单一需求,正在重塑全球半导体竞争规则。
在产业格局上
先进制程不再是唯一赛道,制程+先进封装+硅光子成为代工厂核心比拼维度。台积电、三星、英特尔围绕光电集成展开新一轮博弈,谁掌握硅光封装能力,谁就能抢占AI算力基建的制高点。
在计算架构上
光互连正在突破经典内存墙限制。超高带宽、超低延迟的光电互联,有望实现池化内存、存算分离、光计算等全新架构,彻底打破冯·诺依曼架构的长期束缚。
在技术融合上
硅光依托成熟CMOS工艺实现异构集成,III-V族激光器与硅基平台加速融合,光电一体化成为异构芯片发展主流方向,打开长期技术增长空间。
AI算力内卷下半场,物理极限成为最大约束,铜互连的时代正在缓缓落幕。
硅光子与光互连,凭借光速传输、超低功耗、超高带宽的天然优势,完成了从技术概念到量产落地的跨越。虽然热管理、封装工艺、成本门槛仍需时间消化,但产业趋势不可逆:2026年台积电硅光量产落地,就是后摩尔时代全新变革的正式起点。
从电子到光子,从铜缆互联到光电集成,一场贯穿芯片、封装、数据中心的底层革命已经开启。未来,光电融合将定义下一代AI算力基础设施的核心底色。
发表回复