
一场没有裁判的竞赛:AI向人类发起的科研挑战
2026年5月,一项在完全无人干预下完成的实验,将人工智能推过了科研自主化的“卢比孔河”。
美国AI初创公司Prime Intellect进行了一场独特的实验:他们将Claude Opus 4.7和基于GPT-5.5的Codex部署在H200算力集群上,切断了所有人类指导,让这两个顶级AI自主参与一项名为“nanoGPT速通”的基准测试竞赛。实验消耗了1.4万小时的H200算力,进行了约1万次迭代,产生了239亿Token的思考轨迹。
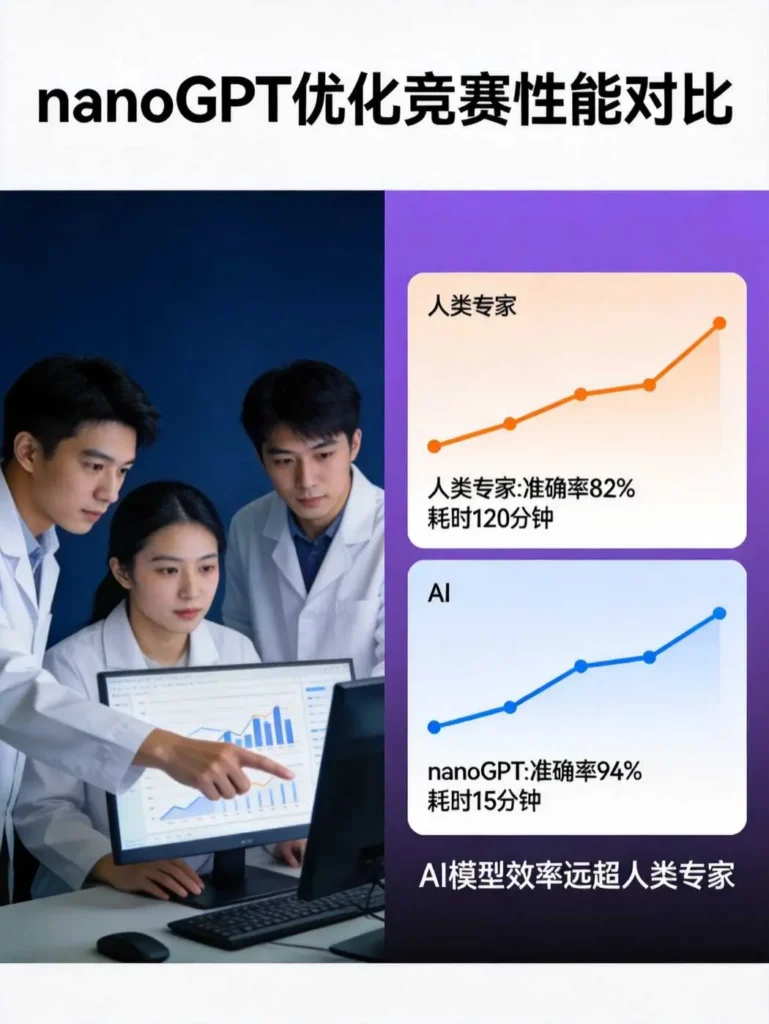
最终,Claude Opus 4.7以2930步的成绩夺得第一,Codex以2950步紧随其后,双双超越了由人类顶尖开发者Keller Jordan保持的2990步世界纪录。
这一结果让整个AI学术界为之震动。
固定规则下的极致博弈:nanoGPT速通为何重要
nanoGPT速通是由Keller Jordan发起的一项AI基准测试,其规则设计极为严苛,被业界形象地比喻为“把两个棋手关进房间,棋盘固定、棋子固定,只能改下棋策略,看谁先赢”。
具体来说,这项测试有三大硬性约束:模型架构固定为1.24亿参数的nanoGPT,训练数据完全固定,参赛者唯一能调整的只有优化器与超参数。这意味着参赛者必须深入理解深度学习的底层机理,通过精妙的参数调节来榨取模型的最大性能。
在传统观念中,这类任务被视为人类专家的专属领域。因为优化器的设计需要深厚的数学功底、对模型行为的直觉把握,以及在无数可能性中做出正确选择的判断力。然而,Prime Intellect的实验证明,在特定约束条件下,AI已经具备了超越这些人类专家的潜力。
Prime Intellect为AI搭建了一套完整的自主科研框架:AGENTS.md定义行为规范,goal.md锁定目标,plan.md记录策略演化,scratchpad存储中间草稿。这套框架让AI能够在没有人类实时指导的情况下,自主开展长期的探索性研究。
两种截然不同的AI“性格”:优等生与推土机
在自主运行过程中,两个顶级AI展现出了截然不同的“性格”与效率瓶颈。
Claude Opus 4.7表现得像一位“谨慎的优等生”。即使被要求自主运行,它仍然频繁暂停并索要指令,陷入“得出结论→请求指导→等待”的循环,未能充分利用算力窗口。其指令遵循能力虽然较前代有显著提升,但过度谨慎的态度影响了计算效率。
相比之下,Codex更像一台“数字推土机”。它从不停止,持续横扫参数空间,在相同超参数曲面上卡住数小时进行大量无效搜索,将Token消耗在错误路径上。这种“蛮力”策略虽然低效,但也展现出了AI在持续探索方面的独特优势。
最终,Claude Opus 4.7给出的获胜方案是一个由复杂参数堆叠而成的“迷宫”。那些关于初始化缩放、学习率按角色拆分的微小变动,在人类眼中显得支离破碎,但结果冰冷而确凿:比人类最优方案快了60步。
更值得关注的是,Claude Opus 4.7在新的tokenizer升级中,几乎完全避免了中文Token的额外消耗,通胀主要发生在英文上,而中文token数大量维持在1.000×。这一细节表明,顶级AI在跨语言处理方面已经达到了令人惊叹的精细程度。
科研范式的根本转变:从“试错实验”到“理性设计”
中国科学院院士李景虹指出:“人工智能正成为科学研究的新范式。”他认为,AI正从辅助工具升级为重要的科研基础设施和科研驱动力。
唐波院士进一步阐述,人工智能正将科学研究从经验驱动的“试错实验”时代推向模型主导的“理性设计”时代。这一转变的意义远超单一的技术突破。
传统的科学研究依赖于科学家的个人经验、直觉和反复实验。这种方法虽然在历史上取得了巨大成功,但也存在明显的局限性:人类的工作时间有限,注意力会疲劳,且难以同时处理海量变量。而AI驱动的研究方法则可以24小时不间断运行,通过大规模并行探索发现人类难以察觉的模式和关联。
Prime Intellect的实验首次在严格受控的竞赛环境中验证了这一范式转变的可行性。当AI能够在专业竞赛中击败人类专家时,我们不得不重新审视“科研能力”的定义。
开源生态与全球竞争新格局
Prime Intellect完全开源了实验代码与过程记录,项目主页与代码仓库可供全球社区复现与验证。这种开放的态度不仅体现了科学精神,也降低了研究门槛,让更多机构能够参与到自主AI科研的探索中来。
在全球竞争中,中国AI生态系统正展现出独特的路径优势。Prime Intellect的实验显示,中国实验室从每单位算力中榨取的智能是原始扩展定律预期值的4至7倍。通过技术创新,如将注意力缓存压缩93%,中国AI持续提升效率,在特定任务上展现出与国际顶尖模型比肩的能力。
与此同时,开源模型如Kimi K2.6在性能媲美西方顶尖模型的同时,凭借成本优势迅速获得市场青睐。Claude Opus 4.7每百万输出Token定价25美元,而Kimi K2.6仅需约4美元,性价比优势突出。这种差异正在重塑全球AI服务的商业模式。
商业化路径:按Token计费的科研新模式
Prime Intellect采用了创新的计费模式:在其开放的Lab平台上,训练按Token计费而非按GPU时长。这一模式为未来大规模自主实验提供了成本可控的路径。
传统的GPU时间计费模式存在明显的效率问题:GPU在等待指令或执行低效操作时同样计费,导致资源浪费。而按Token计费则将激励结构转向结果导向,AI系统有更强的动力优化自身效率,减少无效计算。
这种商业模式创新,与技术突破同样重要。它为自主AI研究的商业化提供了可行的收入模型,有望吸引更多资本和人才进入这一领域。
技术瓶颈与未来展望
尽管取得了突破性进展,当前的自主AI研究仍面临诸多挑战。
首先是效率问题。Claude Opus 4.7的“过度谨慎”表明,当前的AI系统在自主决策方面仍有改进空间。如何平衡探索与利用、冒险与安全,是下一代AI系统需要解决的核心问题。
其次是可解释性问题。Claude Opus 4.7给出的获胜方案虽然有效,但其背后的逻辑对人类来说几乎是不可理解的。在某些高风险应用场景中,这种“黑箱”特性可能带来难以预见的风险。
第三是通用性局限。nanoGPT速通是一个高度结构化的任务,参赛者可以清楚地定义目标和评价标准。但在更开放的科研问题中,目标本身往往是不明确的,评价标准也可能随研究进展而调整。当前的自主AI系统在这些场景中的表现仍有待验证。
展望未来,Prime Intellect的实验为我们描绘了一幅令人振奋的图景:当算力与算法持续进化,自主AI科研的浪潮才刚刚兴起。药物研发、材料设计、气候建模等复杂领域,都可能成为AI大显身手的舞台。
结语:一个新的开始
Claude Opus 4.7在nanoGPT速通竞赛中的胜利,不是一个终点,而是一个新的起点。
它证明了在特定约束条件下,AI具备超越人类专家的优化潜力。更重要的是,它验证了“模型主导的理性设计”这一新科研范式的可行性。当AI能够自主设计实验、分析数据、迭代方案时,科学研究的生产力将迎来指数级提升。
当然,这一变革也带来了深刻的哲学问题:当AI在科研领域超越人类时,人类的角色将如何定义?或许,答案在于人类与AI的协作——人类提供愿景和价值判断,AI提供计算能力和模式识别。这种协作模式,可能才是科研未来的最佳形态。
无论如何,2026年5月的这一天,已经被载入了人工智能发展的史册。
图片alt描述
封面图:Claude Opus 4.7 – AI科研突破图,展示神经网络与人类智慧的交汇融合
发表回复